


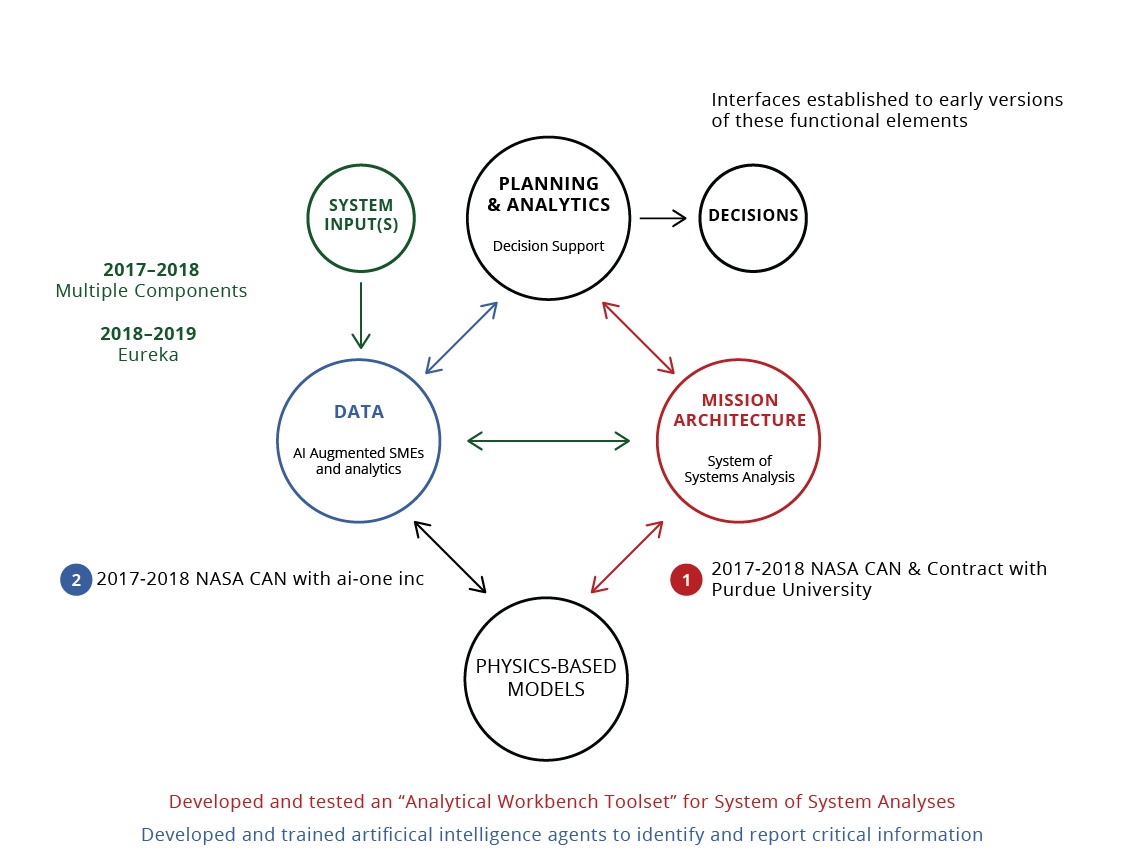
The Eureka Project was designed to tackle this problem by pairing intelligent minds with the power of artificial intelligence.
The goal of the Eureka Project was to enhance the System of System (SoS) analysis toolset by integrating Artificial Intelligence (AI) and formal Model-based Systems Engineering (MBSE) in four key ways:
- Develop and validate AI agents for the dynamic and ongoing collection of pertinent information related to the systems in each architecture, to complement and enhance information from Subject Matter Experts
- Develop methods to rapidly ingest and analyze architectures from multiple sources including formal MBSE-based architectures and systems developed in different MBSE tools
- Test & tune the enhanced toolset using an AI generated/curated Space Architecture Database.
- Begin the development of a digital thread that can link technology status and architecture analysis to requirements and systems development


INDUSTRY WE WORKED WITH

Aerospace



